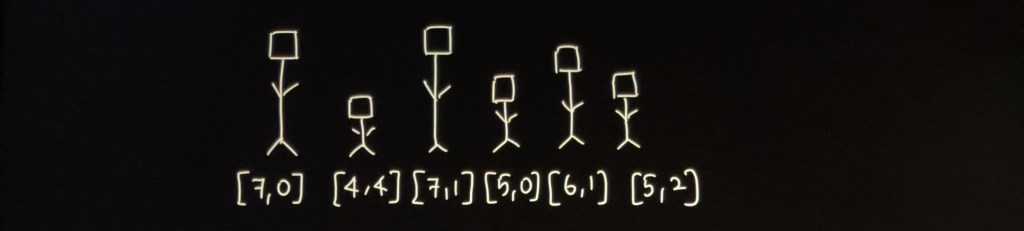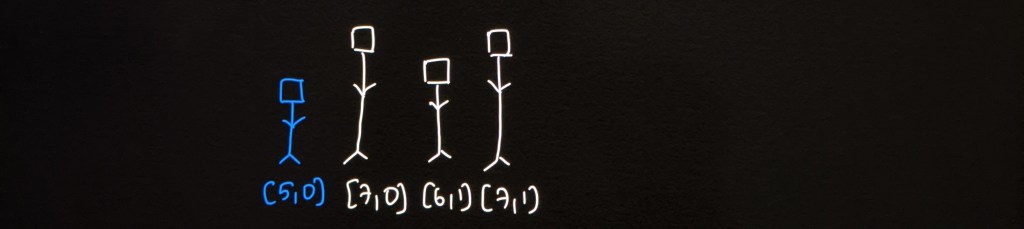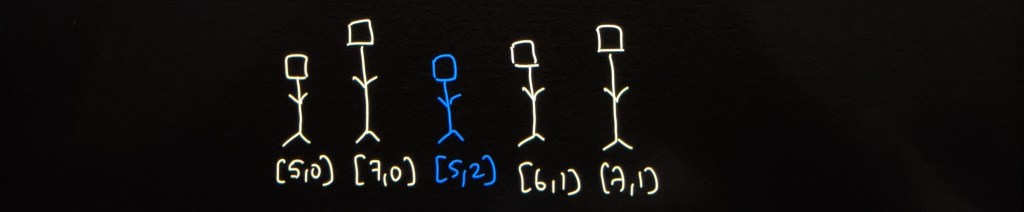There are n cities connected by m flights. We are also given a list with elements containing three pieces of information [u, v, w] where:
- Source city: u
- Destination city: v
- Price to fly from u to v: w
Our goal is to find the cheapest flight ticket from a given source city src to a destination city dst with up to k stops. If no route exists, return -1.
Example 1:
Input:
n = 3, edges = [[0,1,100],[1,2,100],[0,2,500]]
src = 0, dst = 2, k = 1
Output: 200
Explanation:
The graph looks like this:

The cheapest price from city 0 to city 2 with at most 1 stop costs 200, as marked red in the picture.
Solution:
This problem can be re-phrased as trying to find the shortest path between nodes in a weighted graph. Here the nodes are the cities and the weights refer to the flight prices. The simplest graph algorithm to find the shortest path in a weighted graph is Dijkstra’s Shortest Path First algorithm. If this was an unweighted graph, Breadth First Search would have been our ideal choice. This is a good difference to remember. In interviews, the first right move is to model the problem correctly. The next move is to narrow down to the right choice of algorithms.
To solve a graph problem, we have to first construct the graph from the edges. In this problem, for every source city, we store information about the destination cities that we can get to, as well as the corresponding prices. Our constructed graph will look like this.
edges = [[0, 1, 100], [1, 2, 100], [0, 2, 500]]
- 0: [(1, 100), (2, 500)]
- 1: [(2, 100)]
How can we make sure to always pick the path with the lowest weight? What kind of data structure always yields the lowest value? If you haven’t guessed it yet, the answer is a min-heap/ priority queue.
The only catch in this problem is the added restriction of having to reach our destination in at most K stops. Therefore, our priority queue contains elements that hold three key pieces of information.
- The current node src
- The lowest cost to current node
- Minimum number of stops to get to the current node
Note that the priority queue will always give us the element with the lowest cost. We will process the queue as long as there are elements left in it or until we reach the destination dst node. This will be our algorithm at each iteration.
- Pop the lowest cost element from priority queue. This gives us three values curr_node, curr_cost, curr_stops.
- If the curr_node is the same as the destination dst node, return the curr_cost where curr_cost gives the lowest cost with at most K stops to get to the destination.
- If the curr_node is not the destination and curr_stops <= K, then we iterate through the edges of this node stored in our graph. Note that each graph vertex may have multiple routes/ edges to different cities.
- A neighboring edge contains a vertex v and cost c to get there. We will push (v, cost, K) to the priority queue where cost and K are obtained as follows.
- cost = curr_cost + c
- K = curr_stops + 1
Look at the picture below that walks you through the given example step by step.

Time Complexity: The complexity is defined by the number of pop operations we have to do with the min-heap and the number of edges we process for each graph node. Popping from heap takes logarithmic time, so ignoring duplications in the heap, time complexity will be log V. The graph we constructed is an adjacency matrix representation, so the worst case complexity will be V2. The overall complexity is O(V2 log V). Note that the heap complexity will be more than log V since we add the same node to the heap more than once to find the shortest path with K stops.
Space Complexity: O(V2) referring to the maximum space taken up by the adjacency matrix. Conservatively, the heap takes O(V) space.
Code:
def findCheapestPrice(self, n: int, flights: List[List[int]], src: int, dst: int, K: int) -> int:
graph = collections.defaultdict(list)
for s, d, c in flights:
graph[s].append((d, c))
pq = [(0, src, 0)]
while pq:
curr_cost, curr_node, curr_stops = heapq.heappop(pq)
if curr_node == dst:
return curr_cost
if curr_stops <= K:
for dest, cost in graph[curr_node]:
heapq.heappush(pq, (curr_cost + cost, dest, curr_stops+1))
return -1
Hope you enjoyed reading the solution to this problem 🙂 Have a great day!