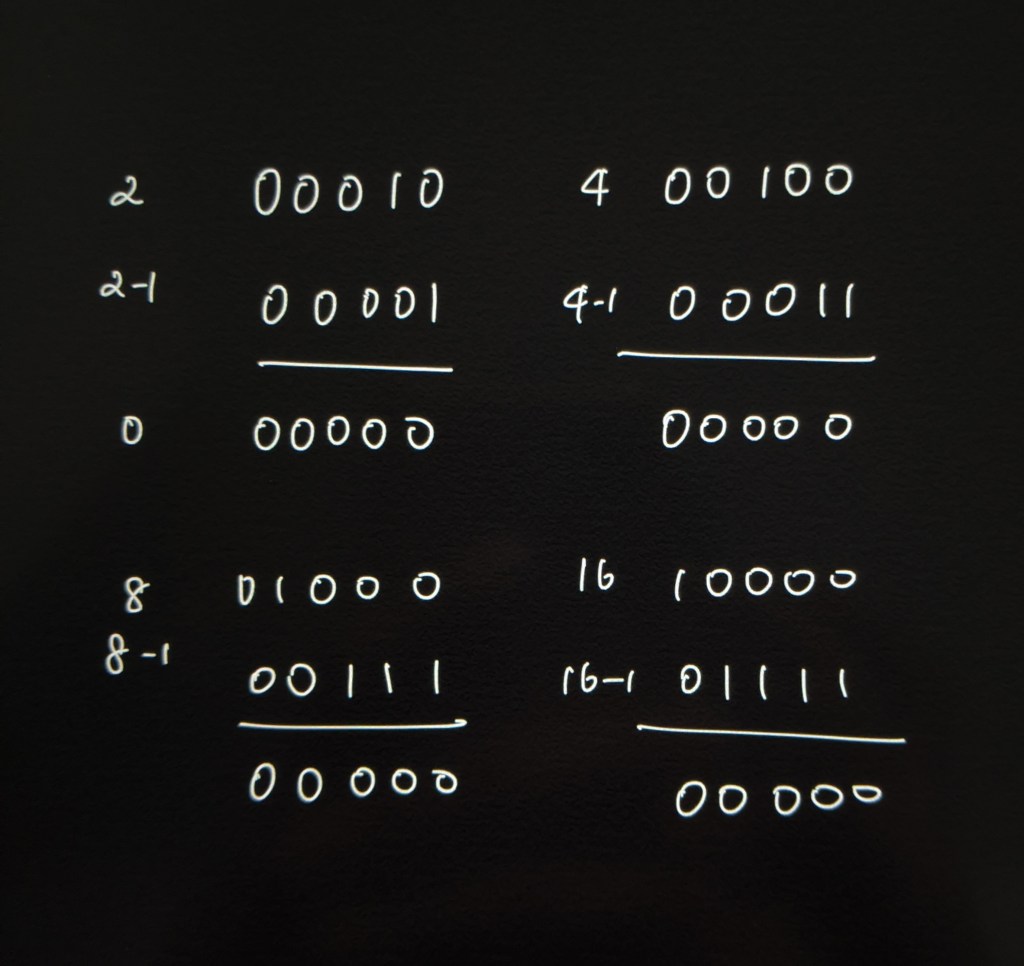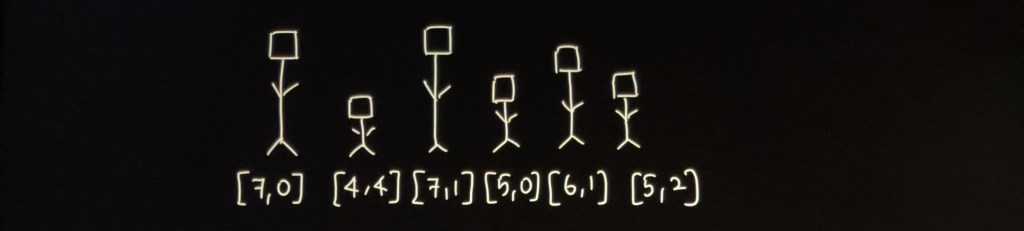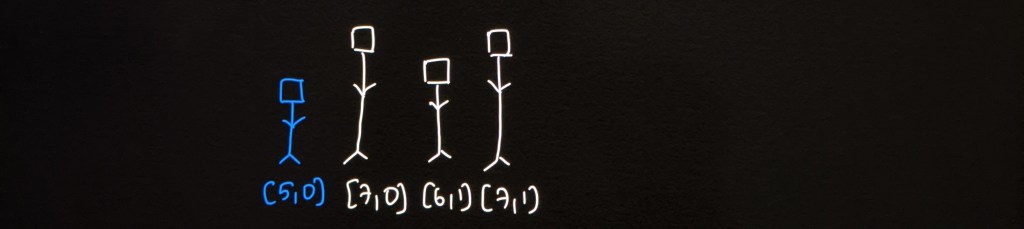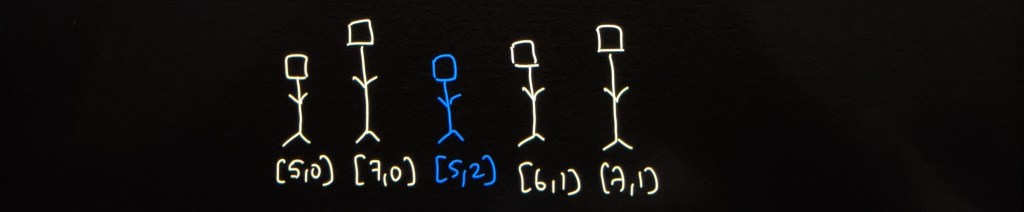Given a set of distinct positive integers, find the largest subset such that every pair (Si, Sj) of elements in this subset satisfies:
Si % Sj = 0 or Sj % Si = 0
If there are multiple solutions, returning any subset is fine.
Example 1:
Input: [1,2,3] Output: [1,2] or [1,3]
Example 2:
Input: [1,2,4,8] Output: [1,2,4,8]
Solution #1:
Let’s say we have a list of numbers as shown below.
nums = [1, 2, 3, 4]
First thing to notice is that every integer is its own largest divisible subset if the given condition does not satisfy for any other element in the list. For example, given a list [5, 7] where neither of them are divisible by each other, the largest divisible subset can be [5] or [7], so both are correct.
Keeping that in mind, a straightforward approach is to check every integer with every other integer in the list to see if the condition Si % Sj = 0 or Sj % Si = 0 is satisfied. Before we begin, we sort the given list so that we can avoid having too many enumerations. Let’s understand this using another example as shown below.
[2, 4, 8]
Note that the list above is sorted in ascending order and all the elements form a divisible subset. If we choose to add one more element d to the divisible subset at front or an element D at the end of the list, all we have to check is whether D % 8 == 0 and 2 % d == 0.
At first we place each integer in its own subset. Then, we can iterate through the list using double for loops and whenever a pair satisfies the given condition, we extend the individual subsets. We start with the following subsets.
[{1}, {2}, {3}, {4}]
Use two pointers i and j where i is used to traverse the sorted list [1, 2, 3, 4]
Calculate the largest divisible subset that ends at the element at i. Use another pointer j to traverse the list until the index i.
If the values at i and j satisfy the divisibility condition ie. nums[i] % nums[j] == 0 and if the (size of the subset at i) < (size of subset at j + 1), then extend the subset at i. This is because we want to extend the subset only if we can get another larger subset, otherwise it’s already the largest subset possible ending with element at i.
To understand clearly, check the example walkthrough below.
Example walkthrough
Once we have all the subsets, we return the one with the max length.
Time Complexity: O(N2) since we use double for loops
Space Complexity: O(N2) for the use of subsets
Code:
def largestDivisibleSubset(self, nums: List[int]) -> List[int]:
if not nums:
return []
nums.sort()
subsets = [{i} for i in nums]
for i in range(len(nums)):
for j in range(i):
if nums[i] % nums[j] == 0 and len(subsets[i]) < len(subsets[j]) + 1:
subsets[i] = subsets[j] | {nums[i]}
return max(subsets, key = len)
Hope you enjoyed learning how to solve the largest divisible subset problem. Have a great day!
Today, we will be discussing one of my favorite problems because it’s open ended and design oriented. We have to design a data structure that can perform insert, delete and get random operations with an average of O(1) time complexity.
insert(val): Inserts an item val to the set if not already present.
remove(val): Removes an item val from the set if present.
getRandom: Returns a random element from current set of elements. Each element must have the same probability of being returned.
Let’s take a look at our toolbox to see what data structures we can use in solving this problem. The table below lists the average time complexity for some of the operations.
Data structure
Access
Insert
Delete
Arrays
O(1)
O(N)
O(N)
Stacks
O(N)
O(1)
O(1)
Queues
O(N)
O(1)
O(1)
Hashmap
O(1)
O(1)
O(1)
Linked List
O(N)
O(1)
O(1)
Average time complexity
The above table shows that most of the data structures except arrays have an average time complexity of O(1) to perform insert and delete operations but remember that inserting and deleting from the end of an array is still O(1). The catch here is to get the getRandom function perform at O(1) time. We cannot get a random index from Hashmaps and accessing indexes takes O(N) time with other data structures except for arrays. In this case, we can leverage the benefits of hashmaps and arrays by doing the following.
Insertion O(1)
Insert an element at the end of an array
Store the insertion indexes of elements in a hashmap
Remove O(1)
Find the index of the element to be removed, from the hashmap
Copy the last element of the array into this index
Pop the last element of the array O(1)
Delete the entry for this element from the hashmap
Get Random O(1)
Use a random function to get an index between 0 and len(array) – 1
Return the element at that index from the array
Time Complexity: All operations happen in O(1)
Space Complexity: O(N) for the array and O(N) for the hashmap, so the overall space complexity is O(N)
Code:
class RandomizedSet:
def __init__(self):
"""
Initialize your data structure here.
"""
self.nums = []
self.mapping = {}
def insert(self, val: int) -> bool:
"""
Inserts a value to the set. Returns true if the set did not already contain the specified element.
"""
if val not in self.mapping:
# Insert the element at the end of nums
self.nums.append(val)
index = len(self.nums) - 1
self.mapping[val] = index
return True
return False
def remove(self, val: int) -> bool:
"""
Removes a value from the set. Returns true if the set contained the specified element.
"""
if val not in self.mapping:
return False
removeIndex = self.mapping[val]
lastValue = self.nums[-1]
# store the last element in the removed val index
self.nums[removeIndex] = lastValue
# Update the index value of last element
self.mapping[lastValue] = removeIndex
# clean up
self.nums.pop()
del self.mapping[val]
return True
def getRandom(self) -> int:
"""
Get a random element from the set.
"""
randIndex = random.randint(0, len(self.nums) - 1)
return self.nums[randIndex]
# Your RandomizedSet object will be instantiated and called as such:
# obj = RandomizedSet()
# param_1 = obj.insert(val)
# param_2 = obj.remove(val)
# param_3 = obj.getRandom()
Hope you enjoyed learning how to design a data structure that can perform insert, delete and get random operations in O(1) time. Have a great day!
Given an array containing integers 0, 1 and 2 representing the colors red, white and blue, sort them in-place so that the same numbers are adjacent, with the order being 0, 1 and 2.
Example:
Input: [2,0,2,1,1,0] Output: [0,0,1,1,2,2]
Solution #1:
There are only three different values in the array and those are 0, 1 and 2. We have to return an array arranged in an order with all the numbers with same values clubbed together. A simple approach is to count the number of 0s, 1s and 2s in the given array and overwrite the given array with these three values according to the counts. In the given array,
count(0) = 2
count(1) = 2
count(2) = 2
So let’s say we store these values in an array counts = [[0, 2], [1, 2], [2, 2]]. We can then iterate through this array and overwrite the given input array with 0, 1 and 2 according to their respective counts.
Time Complexity: O(N) to count the values and another O(N) to overwrite the input array, so the overall time complexity will be O(N).
Space Complexity: O(C) since we use constant space to store the values 0, 1, 2 and their counts.
Solution #2:
Notice that we have to shuffle around only three different values. This means that we can use a few pointers to keep track of some of the values.
Dutch National Flag Problem
Let’s use three different pointers as follows.
zero_ptr to keep track of the leftmost index where we can overwrite with a 0.
two_ptr to keep track of the rightmost index where we can overwrite with a 2.
curr pointer to keep track of the current index we are looking at.
Algorithm to get the Dutch National Flag pattern:
When curr points to a 0, we swap it with the element at zero_ptr. After swapping we move curr and zero_ptr one step forward.
When curr points to a 2, we swap it with the element at two_ptr. We then decrement the value of two_ptr. Note that we should not move curr at this step because we may have just swapped a 2 with another 2 and we should re-process it in the next step.
If curr points to a 1, we just move curr to the next element.
The above loop stops when curr > two_ptr. This indicates that we have placed all the values in their appropriate slots. If this is too confusing, look at the picture below to see how the algorithm works step by step.
Step by step algorithm
Time Complexity: O(N)
Space Complexity: O(1) for in-place re-arrangement
Binary Search is a useful algorithm to search for a target value in a sorted list of elements.
Standard Binary Search:
Get the middle element of the sorted list and compare with the target value. If the number equals the target, we found the value.
If the middle element is less than the target, then we have to search in the right half of the sorted array.
Else we search in the left half of the sorted array.
Let us look at the code for standard Binary Search.
def binarySearch(self, nums: List[int], target: int) -> int:
left = 0
right = len(nums) - 1
while left <= right:
mid = (left + right) // 2
if nums[mid] == target:
return mid
# search in the right half
if nums[mid] < target:
left = mid + 1
# search in the left half
else:
right = mid - 1
return -1
At each iteration of the while loop, the above algorithm divides our search space by half, so the overall time complexity will be O(log N). This is a significant reduction compared to the O(N) time complexity incurred by Linear Search. Now let’s look at a variation.
Binary Search Variation #1:
Given a sorted array and a target value, return the index if the target is found. If not, return the index where it would be if it were inserted in order.
Assumption: There are no duplicates in the array.
In this case, if a target is not found, we have to find the index of the value immediately greater than the target. Let’s look at an example.
Input: nums = [1,3,5,6], target = 4
Output: 2
In the above example, 4 is not present in the array. If we were to insert it into the array, we should insert it between 3 and 5. So our insert index will be 2.
We can use the standard binary search to find the insert position with a slight variation. Let’s run through the algorithm step by step.
left = 0, right = 3
mid = (0 + 3) // 2 = 1
nums[mid] = nums[1] = 3
Here 3 < 4, if nums[mid] < target, search the right half of the list
Then left = mid + 1 => 1 + 1 = 2
left = 2, right = 3
mid = (2 + 3) // 2 = 2
nums[mid] = nums[2] = 5
Here 5 > 4, if nums[mid] > target, search the left half of the list
Then right = mid -1 => 2 – 1 = 1
In the above example, we see that the left pointer holds the insert position as we go through the while loop. This is because, by the time we complete the while loop, left pointer will point to the element that is immediately greater than the target value which is where we will insert our target.
Code:
def searchInsert(self, nums: List[int], target: int) -> int:
left = 0
right = len(nums) - 1
while left <= right:
mid = (left + right) // 2
if nums[mid] == target:
return mid
if nums[mid] < target:
left = mid + 1
else:
right = mid - 1
return left
Binary Search Variation #2:
Now what if we have to find the index of the element that is just smaller than the given target ie., the greatest element lesser than the target value. Yes, you guessed it! This value is stored by the right pointer, so we return it in that case.
Code:
def searchLesserThanTarget(self, nums: List[int], target: int) -> int:
left = 0
right = len(nums) - 1
while left <= right:
mid = (left + right) // 2
if nums[mid] == target:
return mid
if nums[mid] < target:
left = mid + 1
else:
right = mid - 1
return right
Hope you enjoyed learning the different variations of Binary Search. Have a great day!
Given two strings s and t, check if s is a subsequence of t. A subsequence can be formed by deleting some characters in a string without changing the order of the other characters.
Input: s = “abc”, t = “ahbgdc“ Output: true
The simplest way to solve this problem is to use the two-pointer technique where we designate two different pointers to traverse s and t simultaneously. If the characters match, then we move on to check the next character of s against t, otherwise we move on to the next character in t. By the time we are done, there should be no characters left in s to be compared and therefore s must be a substring of t.
Time Complexity: The loop ends when we run out of characters to compare in either s or t. The worst case happens when we run through all the characters in t, so the time complexity is O(T).
Space Complexity: O(1)
Code:
def isSubsequence(self, s: str, t: str) -> bool:
i, j = 0, 0
while i < len(s) and j < len(t):
if s[i] == t[j]:
i += 1
j += 1
return i == len(s)
Testing:
For this problem, the following test cases will cover various situations.
Empty s
Empty t
s string length greater than t
A few other random test cases
I find all other approaches to be kind of an overkill, so I hope you enjoyed this simple approach. Have a great day!
n & (n -1) is a pretty powerful bitwise operation and we will see why in this post.
Power of two
Given an integer, we have to write a function to determine if it is a power of two.
Examples:
Input: 1 Output: true Explanation: 20 = 1
Input: 32 Output: true Explanation: 25 = 32
Input: 100 Output: false
What do powers of two look like in binary representation?
1 – 1
2 – 10
4 – 100
16 – 1000
32 – 10000
Notice that the integers above have only one 1-bit followed by all zeroes.
When we subtract 1 from any number, the rightmost 1-bit gets set to 0 and all the bits following this rightmost 1-bit will be set to 1. Let’s look at a few examples. In binary subtraction, when we perform 0 – 1, the result is 1 with a borrow of 1 from the next higher order bit. Borrowing can be tricky, here is good video that goes over binary subtraction.
Subtract 1
When we AND the results above with the original integers, the result is 0. To conclude, if n & (n – 1) equals zero, then the given integer is a power of two. Other numbers have more than one 1-bit in the binary representation, so this trick will not return zero for those cases.
n & (n-1)
Time Complexity: O(1)
Space Complexity: O(1)
Code:
def isPowerOfTwo(self, n: int) -> bool:
if n == 0:
return False
return n & (n-1) == 0
Count the number of ones in an unsigned integer
Essentially what n & (n-1) does is that it sets the right most 1-bit in an integer to 0. If we do that repeatedly, at some point all the bits get set to 0. We can use this same expression to count the number of one bits in any given unsigned integer without having to count the ones by traversing bit by bit. The number of 1-bits in an integer is also known as the hamming weight of a number.
Time Complexity: An unsigned integer will be 4 bytes ie., 32 bits long at maximum. The worst case happens when all the bits of an integer are 1 and we have to loop through it 32 times setting the rightmost bits to 0. If we consider this to be a constant time operation since an integer can never have more than 32 bits, then the time complexity will be O(1).
Space Complexity: O(1)
Code:
def hammingWeight(self, n: int) -> int:
count = 0
while n:
n &= n-1
count += 1
return count
Hope you had fun learning this useful bit manipulation trick. Have a nice day!
We are given a list of people described by height h and a number k. k refers to the number of people in front of this person who are of height greater than or equal to their height. We have to write an algorithm to reconstruct the queue.
Let’s manually try to place the people in a queue. The given list looks like this.
Given list
We first take the tallest person and place them in the queue according to their index value. If two people have the same index value, then we give priority to the person who is shorter. We will see why in a bit. So the queue will look like this after placing [7, 0] and [7, 1].
Place [7, 0] and [7, 1]
Next, we pick the next tallest person in queue [6, 1]. When we try to place them in the index 1, there is already a person of height 7 there. In this case, we need to place the person with the shorter height in front because they should have only 1 more person who is of equal height or is taller than them. We insert this person in the queue before [7, 1]. The queue will now look like this.
Insert [6, 1]
We can pick the next tallest person with height 5. We can place [5, 0] before placing [5, 2] since the lower index person gets priority. 0th index already has a person of height 7, but we will push them back and insert [5, 0] to let the shorter person be in the front. The queue will now look like this.
Insert [5, 0]
Let’s continue doing this for the left out elements and we will get the following.
Insert [5, 2]
Insert [4, 4]
The code for this algorithm involves two steps:
Arrange people in descending height. When there is a tie in height, give priority to the one with the lower index.
Insert people according to their indexes into a new queue. When there is a tie in index, give priority to the one with the lower height.
Time Complexity: O(NlogN) for sorting and O(N) to insert an element into a list, so the overall complexity to insert N elements will be O(N2).
Space Complexity: We will do the sorting in place and the result queue need not be considered as extra space, so space complexity is O(1).
Code for the above solution:
def reconstructQueue(self, people: List[List[int]]) -> List[List[int]]:
# sort people by descending height and ascending index k
people.sort(key = lambda x: (-x[0], x[1]))
results = [] * len(people)
for p in people:
results.insert(p[1], p)
return results
Hope you enjoyed reading this post. Have a great day!
Today’s problem is a very interesting one but is usually worded poorly in most places.
We are given an array W of positive integers where W[i] refers to the weight of index i. We have to write a function called pickIndex which will randomly pick an index proportional to its weight. Let’s look at an example to understand this better.
W = [1, 2, 3, 4, 5]
In the above case the weights are as follows.
W[0] = 1
W[1] = 2
W[2] = 3
W[3] = 4
W[4] = 5
How do we randomly pick an index proportional to its weight?
The weights of all the indexes in the array sum to 15 (1 + 2 + 3 + 4 + 5).
For index i = 0 with weight = 1, we have to pick this index once out of 15 times
For index i = 4 with weight = 5, we have to pick this index five out of 15 times
The bottomline line is that the indexes with the higher weights should have high probability of being picked, in this case that probability is:
P(i) = W[i] / sum(W)
ie., for index = 4 P(4) = 5/ 15 = 1/ 3.
Solution #1:
For probability problems, one of the foremost things we need is a sample space. Let’s simulate this using a generated array with 15 entries where each entry corresponds to an index in the array and appears W[i] number of times. For example, the index 4 should appear W[4] = 5 times in the array.
If we are to pick a number randomly from the above list, we have solved the problem of picking a random index proportional to its weight.
Time Complexity: The time complexity will be O(sum(W)) to generate the sample space array.
Space Complexity: The simulated array will cost us O(sum(W)) extra space.
Code for solution #1:
class Solution(object):
def __init__(self, w: List[int):
totalSum = sum(w)
table = [0] * totalSum
i = 0
for j in range(0, len(w)):
for k in range(i, i + w[j]):
table[k] = j
i = i + w[j]
self.size = len(table)
self.table = table
def pickIndex(self) -> int:
randomIdx = random.randint(0, self.size - 1)
return self.table[randomIdx]
# Your Solution object will be instantiated and called as such:
obj = Solution(w)
param_1 = obj.pickIndex()
The above solution is extremely memory intensive since we generate an array that’s mostly larger than the input array itself to simulate the sample space.
Solution #2:
The total sum of our weights sum(W) is 15. If we had to draw a line and divide it according to the given weights ranging from 1 to 15, how would that look like?
Instead of generating an entirely new array with the repeated indexes, we can calculate the prefix sums for each index. The formula to find the prefix sum of W[i] is shown below.
W[i] = W[i] + W[i-1]
Then our prefix array will look like this.
W = [1, 3, 6, 10, 15]
The total weight 15 is the length of our sample space. We will first generate a random number between 1 and 15.
randIndex = random.randint(1, maxWeight)
Let’s say that the randIndex returns 8. This index falls in the range (6 – 10]. So we return the index filling up this range which is 3.
Find randIndex ranges
If the randIndex returns 15, this number falls in the range (10 – 15]. So we return the index filling up this range which is 4.
We find this range using linear search on the prefix sum W array. All we have to find a value such that value <= randIndex which indicates that it has fallen in that particular range. In that case, we return the index of this value.
Time Complexity: O(N) to calculate prefix sum and O(N) to find the randIndex value in the prefix sum array. This means the pickIndex function call runs in O(N) time.
Space Complexity: O(1) since we are not using any extra space.
Code for solution #2:
class Solution:
def __init__(self, w: List[int]):
# Calculate the prefix sums
w = list(itertools.accumulate(w))
self.w = w
if self.w:
self.maxWeight = self.w[-1]
else:
self.maxWeight = 0
def pickIndex(self) -> int:
randIndex = random.randint(1, self.maxWeight)
for i, prefixSum in enumerate(self.w):
if randIndex <= prefixSum:
return i
return 0
#Your Solution object will be instantiated and called as such:
obj = Solution(w)
param_1 = obj.pickIndex()
Solution #3:
In the above solution pickIndex() runs in O(N) time and it’s basically doing a linear search in the array to find the range of the randIndex. We can improve the time complexity using binary search.
In the binary search algorithm, if our randIndex value matches an entry in the prefix sums array, we return that index. Else we return the index of a value which is <= randIndex. This is basically a binary search to find a number N such that N <= target.
Time Complexity: O(logN) to pick the index.
Space Complexity: O(1)
Code for solution #3:
class Solution(object):
def __init__(self, w: List[int]):
w = list(itertools.accumulate(w))
self.w = w
if self.w:
self.maxWeight = self.w[-1]
else:
self.maxWeight = 0
def pickIndex(self) -> int:
randIndex = random.randint(1, self.maxWeight)
# Binary search for randIndex
left = 0
right = len(self.w) - 1
while left <= right:
mid = (left + right) / 2
if self.w[mid] == randIndex:
return mid
if self.w[mid] < randIndex:
left = mid + 1
else:
right = mid - 1
return left
# Your Solution object will be instantiated and called as such:
obj = Solution(w)
param_1 = obj.pickIndex()
Solution #4 (Optional):
The code in solution #3 can be written in a very pythonic way using built-in functions as shown below. The time and space complexity will be the same.
Python’s bisect.bisect_left() returns an insertion point i that partitions the array into two halves such that all(val < randIndex for val in w[left : i]) for the left side and all(val >= randIndex for val in a[i : right]) for the right side. Read more here.
class Solution:
def __init__(self, w: List[int]):
self.w = list(itertools.accumulate(w))
def pickIndex(self) -> int:
return bisect.bisect_left(self.w, random.randint(1, self.w[-1]))
#Your Solution object will be instantiated and called as such:
obj = Solution(w)
param_1 = obj.pickIndex()
Hope you learnt to methodically approach the random pick with weight problem. Have a nice day!
Write a function that reverses a string. The input string is given as an array of characters char[].
Input: A = [“h”,”e”,”l”,”l”,”o”] Output: [“o”,”l”,”l”,”e”,”h”]
Solution #1: Arrays ie., lists in Python are mutable data structures which means they can be modified in place without having to allocate extra space. For this problem, creating a new array using the input array is a trivial solution. So let’s directly dive into an O(1) memory solution.
In Python, we can refer to the elements in reverse order starting at the index -1.
A[-1] = “o”
A[-2] = “l”
A[-5] = “h”
This is quite helpful in manipulating array indexes. In order to reverse the elements, we don’t have to traverse the full list but swap the first half of the list with the second half starting from the end.
ie., swap A[i] with A[-(i+1)] for i = 0 to i = len(A) / 2
Time Complexity: We traverse only half the list while swapping elements with the second half of the list. So the time complexity will be O(N/2) which is O(N) overall.
Space Complexity: O(1)
Code for solution #1:
def reverseString(self, s: List[str]) -> None:
"""
Do not return anything, modify s in-place instead.
"""
for i in range(len(s) // 2):
s[i], s[-(i+1)] = s[-(i+1)], s[i]
Solution #2: A Python in-built function that does exactly what we did above is reverse(). The list is modified in place by swapping the first half of the list with the second half the same way as shown above. Read more about reverse() here.
Solution #3:If we are allowed to create and return a new list, then we can use Python reversed() function as shown below. reversed() returns an iterator in Python, so we have to wrap its result in a list(). Read more about it here.
Space Complexity: O(N) since we are creating a new list.
What if we are given a string and not an array of characters?
An important distinction here is that strings are immutable, so we cannot leverage any in-place reversals here. Let’s look at some Pythonic ways of reversing a string.
Input: “hello”
Output: “olleh”
Solution #4: Using Python’s elegant index slicing.
Space Complexity: O(N) since a new string is created.
Solution #5: Another way to improve the readability of your code instead of using the above syntax which a non-python developer may not immediately be able to comprehend is to use reversed() to reverse a string.
Use reversed() to create an iterator of the string characters in the reverse order.
Use join to merge all the characters returned by the iterator in the reverse order.
Space Complexity: O(N) since a new string is created.
Let’s summarize all the different ways.
Input
Method
Time Complexity
Space Complexity
list[str]
Swap elements from first half with second half of the array.
O(N)
O(1)
list[str]
Built-in list.reverse()
O(N)
O(1)
list[str]
list(reversed(s))
O(N)
O(N)
str
Slicing str[: : -1]
O(N)
O(N)
str
“”.join(reversed(str))
O(N)
O(N)
Comparison of string reversal methods
Hope you learnt many Pythonic ways to reverse a string or an array of chars[]. There are many non-Pythonic ways as well which we will discuss in a separate post. Have a great day!
The cost of flying the ith person to city A is costs[i][0]
The cost of flying the ith person to city B is costs[i][1]
A company is planning to interview 2N people. Return the minimum cost to fly every person to a city such that exactly N people arrive in each city.
Example:
Input: [[10, 20], [30, 200], [400, 50], [30, 20]] Output: 110 Explanation: The first person goes to city A for a cost of 10. The second person goes to city A for a cost of 30. The third person goes to city B for a cost of 50. The fourth person goes to city B for a cost of 20.
The total minimum cost is 10 + 30 + 50 + 20 = 110 to have half the people interviewing in each city.
Assumption:
The costs list will always have an even length.
Solution:
First let’s try to understand the problem statement clearly.
What we need to do is out of N given people and their costs, exactly N/2 people should be flown to city A and other N/2 people need to be flown to city B.
This means for N/2 elements in the costs list, we have to choose the costs[i][0]th element and for the other N/2 elements, we need to choose the costs[i][1]th element.
The part that needs to be solved is to choose elements such that the overall cost is minimized.
The first thing that pops in our heads is to find out if we can somehow sort this given list. Let’s look at an example.
[[10, 20], [10, 20], [10, 40], [10, 50]]
We can sort by the first element of the list of lists ie., costs[i][0]. This will ensure that the list is sorted by the lowest costs to fly to city A. In this case, the list remains the same.
[[10, 20], [10, 20], [10, 40], [10, 50]]
If we choose the first N/2 people this way to fly to city A and the next N/2 people to fly to city B, we are not guaranteed that the sum of costs to fly to B will be minimum.
Sum(A) = 10 + 10 = 20
Sum(B) = 40 + 50 = 90
Total cost = 20 + 90 = 110 Wrong answer!
In order to get the optimal cost, we have to fly the first two people to city B and the next two to city A. Remember that we cannot fly the same person to both city A and city B!!
Sum(A) = 10 + 10 = 20
Sum(B) = 20 + 20 = 40
Total cost = 20 + 40 = 60 Voila!
Using the given elements in the list, we cannot directly sort it such that the cost is minimized. So, what can we do with the given values? Let’s look at the costs on a case by case basis.
[10, 20] – The cost of sending this person to city A vs city B is 10 – 20 = -10
[10, 20] – The cost of sending this person to city A vs city B is 10 – 20 = -10
[10, 40] – The cost of sending this person to city A vs city B is 10 – 20 = -30
[10, 50] – The cost of sending this person to city A vs city B is 10 – 20 = -40
Since we are subtracting cost(B) from cost(A), if the difference is low, it means it’s better to send this person to city A and when the difference is very high, we send them to city B. Now let’s say we have costs for a person as [400, 50]. The cost of sending this person to city A vs city B (cityA – cityB) is +$350!! We might as well send them to city B. So that’s what we will do.
We will sort the costs by the difference cost(A) – cost(B) from low to high. For the first N/2 people of this sorted list, we send them to city A and for the next N/2, we send them to city B.
Time Complexity: Sorting takes O(N log N), so this will be O(N log N) + O(N/2) + O (N/2). So the overall complexity is O(N log N).
Space complexity: If we are doing an in-place sort, then the space complexity will be O(1)
Code for the above solution:
def twoCitySchedCost(self, costs: List[List[int]]) -> int:
minCost = 0
N = len(costs)
costs.sort(key = lambda x: x[0] - x[1])
for i in range(N // 2):
minCost += costs[i][0]
for i in range(N // 2, N):
minCost += costs[i][1]
return minCost
Testing:
You can test the following cases.
Any given test case: [[10,20],[30,200],[400,50],[30,20]]
Case where cost to city A is the same and vice versa: [[10,20],[10,20],[10,40],[10,50]]
Case where cost(A) = cost(B): [[10,10],[200,200],[400,400],[30,30]]
A random case mixed with the above two cases: [[20,10],[400,200],[100,400],[3,30], [3,30],[40,40]]
Hope you learnt how to solve the two city scheduling problem. Have a nice day!