In this blog post, we will take a deep dive into cURL which stands for “Client URL”. It is a command line tool that helps in transferring data to and from a server to a client. cURL supports a lot of different protocols such as HTTP, HTTPS, FTP etc. cURL uses the libcURL URL transfer library.
This blog post contains the following sections.
- Introduction to API Testing
- cURL Installation
- Commonly Used cURL Options
- cURL Methods
- Practical Example – Google Books API
Introduction to API Testing
API stands for Application Programming Interface which is a set of rules and protocols that allows a client to interact with a software. An API contains
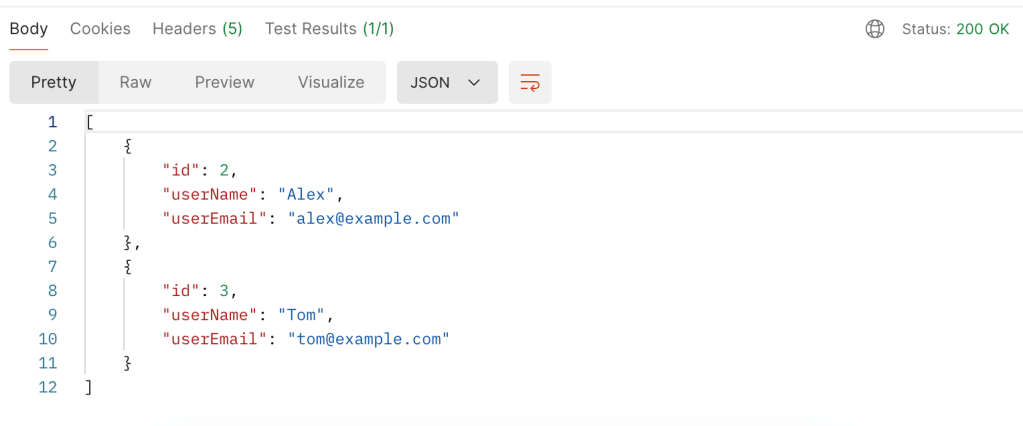
- Endpoints – these are specific URLS that a client can use to access different methods and resources. Ex: /users, /texts
- Requests and Responses – Clients send requests to a server endpoint which in turn sends back responses.
- Data format – APIs can use various formats such as JSON or XML etc for the data being transferred between the client and the server.
- Authentication – APIs are more secure when they verify identity of a user and require authorization before exchange of data. This can be achieved using API Keys, OAuth, Tokens etc.
- Methods – Includes methods such as GET, DELETE, PUT, POST etc which perform various actions.
There are different types of API protocols but REST and SOAP are some of the most popular ones. In this blog post, we will use REST protocol to understand cURL commands.
There are various popular API Testing Tools such as Postman, SoapUI, REST Assured, Katalon Studio etc.
cURL Installation
I have a macOS so I use brew. But please follow the instructions here to install cURL based on your operating system.
brew install curl
Commonly Used cURL Options
–X: Specify request method (GET, POST etc.)
curl -X GET https://myurl.org/users
-d: Send data in POST request
The “&” is used to separate the key=value pairs. You can also use -F parameter to pass form data as name=value pairs.
curl -d "name=john&id=2" https://myurl.org/users
curl -F name=john -F id=2 https://myurl.org/users
-H: Request headers
curl -H 'User-Agent: Chrome' -H 'Host: www.myurl.org' https://myurl.org/
Users can use a Bearer token for authorization as well. The bearer token is an encrypted string that provides authentication for a client to get access to protected resources.
curl -H "Authorization: {Bearer token}" https://myurl.org/
-I: Fetch only the HTTP Headers
This is the HTTP HEAD method to get only a resource’s HTTP headers.
curl -I https://myurl.org/
-o: Save output to a file (files with same name will be overwritten)
curl -o picture.png https://myurl.org/pictures/picture-3.png
-L: Redirect
Tell curl to follow redirect requests since curl does not perform 300 redirect requests.
curl -L https://myurl.org
-u: Username and password specification
curl -u {username}:{password} https://myurl.org
-c: Save cookies to a file
This will save the cookies returned by the server in the cookies.txt file.
curl -c cookies.txt https://myurl.org
-b: Read cookies from a file
curl -b cookies.txt https://myurl.org
To activate the cookie engine and read cookies. cURL will see the “=” and know that cookies are specified.
curl -b {cookie-name}={cookie-value} https://myurl.org
-x: Use proxies
curl -x https://{proxyhost}:{proxyport} https://myurl.org/data
cURL Methods
There are four important cURL methods – GET, POST, PUT and DELETE.
GET Request
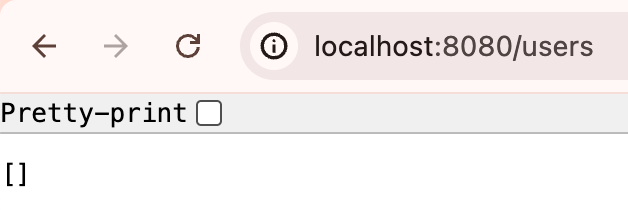
This is the default method when making HTTP calls with curl. The following example fetches all the users from the url.
curl https://myurl.org/users
POST Request
POST is used to send data to a receiving service. We can do this using the data or -d option.
curl -X POST -d "name=john&id=2" https://myurl.org/users
PUT Request
PUT is used to update an existing resource. In this case update the user id #1.
curl -X PUT -d "name=john&id=2" https://myurl.org/users/1
DELETE Request
This example deletes the user id #1.
curl -X DELETE https://myurl.org/users/1
Practical Example – Google Books API
Now let’s walk through an actual example in the code below. In the following example, let’s use the Google Books API.
Requests need to be authenticated using the API key or OAuth. Follow the instructions in the link above to get an API key that you can use for the request below.
#!/bin/bash
# Replace with your actual API key
API_KEY="{API_KEY}"
# Define the base URL for the Google Books API
BASE_URL="https://www.googleapis.com/books/v1"
# URL-encode the query term. Harry Potter becomes "Harry%20Potter"
QUERY="Harry Potter"
ENCODED_QUERY=$(echo "$QUERY" | jq -sRr @uri)
# Function to search for books by a query
search_books() {
echo "Searching for books with query: $QUERY"
curl -s "${BASE_URL}/volumes?q=${ENCODED_QUERY}&key=${API_KEY}" | jq '.items[] | {title: .volumeInfo.title, authors: .volumeInfo.authors, publisher: .volumeInfo.publisher, publishedDate: .volumeInfo.publishedDate}'
}
# After URL encoding, J.K. Rowling becomes "J.K.%20Rowling"
AUTHOR="J.K. Rowling"
ENCODED_AUTHOR=$(echo "$AUTHOR" | jq -sRr @uri)
# Function to list books by a specific author
list_books_by_author() {
echo "Listing books by author: $AUTHOR"
curl -s "${BASE_URL}/volumes?q=inauthor:${ENCODED_AUTHOR}&key=${API_KEY}" | jq '.items[] | {title: .volumeInfo.title, publisher: .volumeInfo.publisher, publishedDate: .volumeInfo.publishedDate}' | head -n 20
}
# Main script execution
search_books
# List books by author
list_books_by_author
The output of the above bash script will be as follows.
Searching for books with query: Harry Potter
{
"title": "Harry Potter and the Sorcerer's Stone",
"authors": [
"J.K. Rowling"
],
"publisher": "Pottermore Publishing",
"publishedDate": "2015-12-08"
}
{
"title": "Harry Potter and the Chamber of Secrets",
"authors": [
"J.K. Rowling"
],
"publisher": "Pottermore Publishing",
"publishedDate": "2015-12-08"
}
{
"title": "Harry Potter and the Prisoner of Azkaban",
"authors": [
"J.K. Rowling"
],
"publisher": "Pottermore Publishing",
"publishedDate": "2015-12-08"
}
{
"title": "Harry Potter and the Cursed Child",
"authors": [
"J. K. Rowling",
"Jack Thorne",
"John Tiffany"
],
"publisher": null,
"publishedDate": "2017"
}
{
"title": "The Irresistible Rise of Harry Potter",
"authors": [
"Andrew Blake"
],
"publisher": "Verso",
"publishedDate": "2002-12-17"
}
{
"title": "The Psychology of Harry Potter",
"authors": [
"Neil Mulholland"
],
"publisher": "BenBella Books, Inc.",
"publishedDate": "2007-04-10"
}
{
"title": "Harry Potter and the Half-Blood Prince",
"authors": [
"J.K. Rowling"
],
"publisher": "Pottermore Publishing",
"publishedDate": "2015-12-08"
}
{
"title": "Fantastic Beasts and Where to Find Them: The Illustrated Edition",
"authors": [
"J. K. Rowling",
"Newt Scamander"
],
"publisher": "Arthur A. Levine Books",
"publishedDate": "2017-11-07"
}
{
"title": "JK Rowling's Harry Potter Novels",
"authors": [
"Philip Nel"
],
"publisher": "A&C Black",
"publishedDate": "2001-09-26"
}
{
"title": "The Magical Worlds of Harry Potter",
"authors": [
"David Colbert"
],
"publisher": "Penguin",
"publishedDate": "2008"
}
Listing books by author: J.K. Rowling
{
"title": "Conversations with J. K. Rowling",
"publisher": null,
"publishedDate": "2002-01-01"
}
{
"title": "Harry Potter and the Walls of America",
"publisher": "Createspace Independent Publishing Platform",
"publishedDate": "2017-01-01"
}
{
"title": "Harry Potter and the Philosopher's Stone - Ravenclaw Edition",
"publisher": "Bloomsbury Children's Books",
"publishedDate": "2017-06"
}
{
"title": "Harry Potter and the Philosopher's Stone",
"publisher": "Bloomsbury Harry Potter",
"publishedDate": "2001"
}
Hope you are now confident with making cURL requests! In the next blog post, let us look into Postman in detail – an API testing tool that makes things way easier for API development.