
Semantic search is a type of search that takes into account the meaning and context of a query from a user as opposed to lexical search which only looks for exact keyword match of the query terms.
As an example, when a user searches for the term “football”, we want the search to also consider words such as “soccer”. When “football” is misspelled as “ftball”, we still want to match with “football”.
Semantic search has the ability to dramatically improve the user experience by improving the quality of search results. This is achieved by various Machine Learning models and AI technologies.

Structured Vs Unstructured Data
Structured data is well-defined and is easily searchable whereas unstructured data can be anything such as photos, audio, videos, paragraphs of texts, emails etc and is harder to search through.
Structured data fits well into a storage solution such as a relational database and is searchable using SQL queries but unstructured data does not and needs to be processed using machine learning algorithms to get relevant search results.
As much as 80% of data out there is unstructured. This is important for semantic search because it works on unstructured data which needs to be indexed in a way that it is searchable as efficiently as possible.
Transforming Unstructured Data Using Vector Embeddings
In order for Machine Learning algorithms to process unstructured data to get the most relevant results, this data needs to be represented in a way that the ML models can understand.
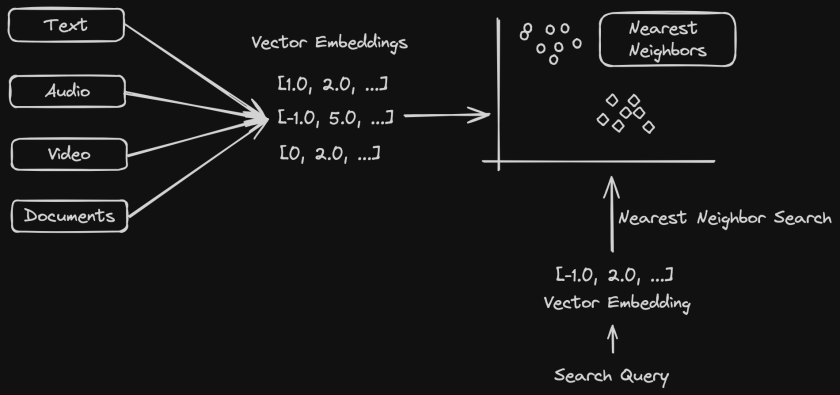
This is where Vector Embeddings become useful. Vector Embeddings represent data in numerical form. This opens up a world of computational possibilities on this data. Vector Embeddings transform unstructured data into points in the vector space where similar points get clustered together. This means words, sentences, audio data etc can be represented as vectors which get clustered together in an n-dimension vector space according to their similarity. This is then used by machine learning algorithms to find patterns using which we can do queries that find the most relevant search results.

Here is an example of a 5 dimensional vector embedding. Each point in the vector refers to a feature representing the data.
[1.0, 3.0, 5.0, 7.0, 9.0]
There are various types of embeddings such as word embeddings, graph embeddings, image embeddings etc. The most common type of embeddings used are word embeddings which is used to represent textual data and is used in Semantic Search.
Indexing Vector Data
When data is represented as vector embeddings, it can have high dimensionality based on the number of features used to represent the data. We therefore need a way to efficiently search through large sets of vector embeddings.
Indexing the vector data in the right way helps in efficiently retrieving the most relevant results during search. There are various indexing algorithms proposed for this but a couple of them are highly popular.
Locality Sensitive Hashing (LSH)
This technique is used to do an approximate nearest neighbor search in high dimension vector space. LSH is a hashing based algorithm that will hash similar points to the same or nearby buckets with a high probability so that the search space reduces. Collisions are maximized for similar inputs unlike traditional hashing where we minimize them. This makes it faster to find the approximate nearest neighbors.
Some parameters that need tuning to achieve a good trade off between accuracy and efficiency are hash size, number of hashing functions, number of hash tables etc.
Hierarchical Navigable Small Worlds (HNSW)
HNSW is a graph based data structure that can be used for approximate nearest neighbor search. This works great for high dimensionality vector data since it navigates the graph efficiently for similarity search.
The graph data structure is organized into levels with the bottom layer containing the most data points and each layer above it being a subset of the previous one. The vertices are created such that the likelihood of a graph node appearing in top layers decreases exponentially, which helps keep the graph sparse at higher levels enabling efficient search.
During a search operation, we start at the top most layer and navigate towards the bottom of the graph to find the nearest neighbors that decrease the distance to the input data points. This means we are searching more coarsely at the top instead of having to search the entire graph and keep refining the search as we get to the bottom layer.

In the example above, we want to find the nearest neighbor of the red dot. So we start at the top most layer at an entry point node and traverse to the neighbor, we then go to the next levels to try and find the nearest neighbor. This is an oversimplification of HNSW works but we will look at this topic in detail on another post.
HNSW are efficient and have good accuracy, thereby being the most popular algorithm for vector similarity search at the moment. HNSW may not suit data that gets frequent updates since reconstructing the graph often is an expensive process.
Searching on Vector Data
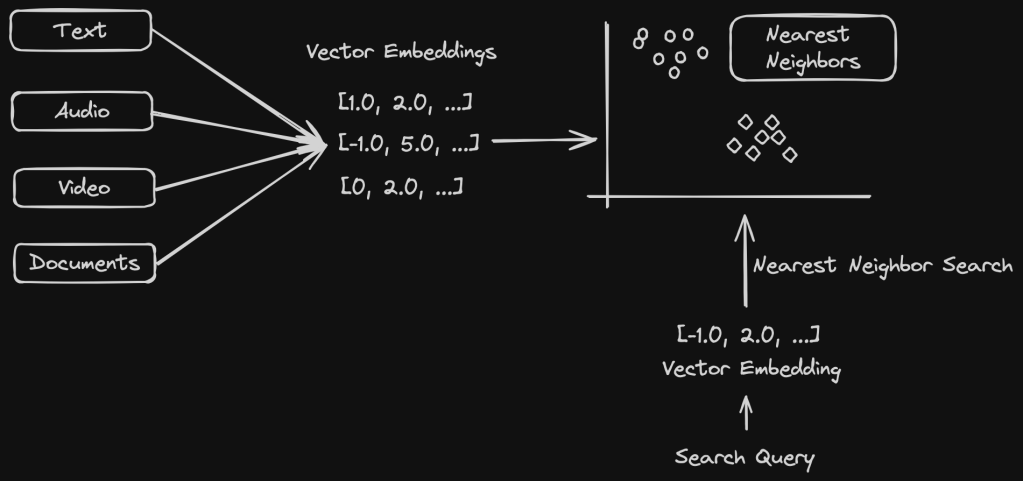
Vector search also known as nearest neighbor search is what powers several semantic search use cases. This works efficiently on vector embeddings that we learnt about in the previous section. Since the search query is also represented as a vector, finding the most relevant results would mean searching for the nearest neighbors for the given query data.
The most popular algorithm for doing a nearest neighbor search in kNN – k nearest neighbor search. This provides highly accurate results but it is also computationally intensive. For large language model datasets, this does not scale well. So in these cases, the ANN – Approximate Nearest Neighbor search works much better at the cost of slightly reduced accuracy. We will learn about KNNs and ANNs in future posts on this topic.
Hope you enjoyed learning about semantic search. Let’s continue to explore this topic in more detail.

One thought on “Introduction to Semantic Search”